TL;DR
- Visual datasets with millions of images and metadata can create massive LLM context windows (tens of millions of tokens) leading to context explosion.
- Visual Layer's chat interface resolves this with a dynamic, tool-based orchestration architecture, allowing natural language exploration of these datasets.
- This drastically reduces token consumption.
- This article, Part 1, covers preventing context explosion.
Introduction
Visual datasets now contain millions of images, labels, and custom metadata. This means naive LLM-based exploration easily exceeds any [context window][rte1]. Sending full metadata can reach tens of millions of tokens per query.
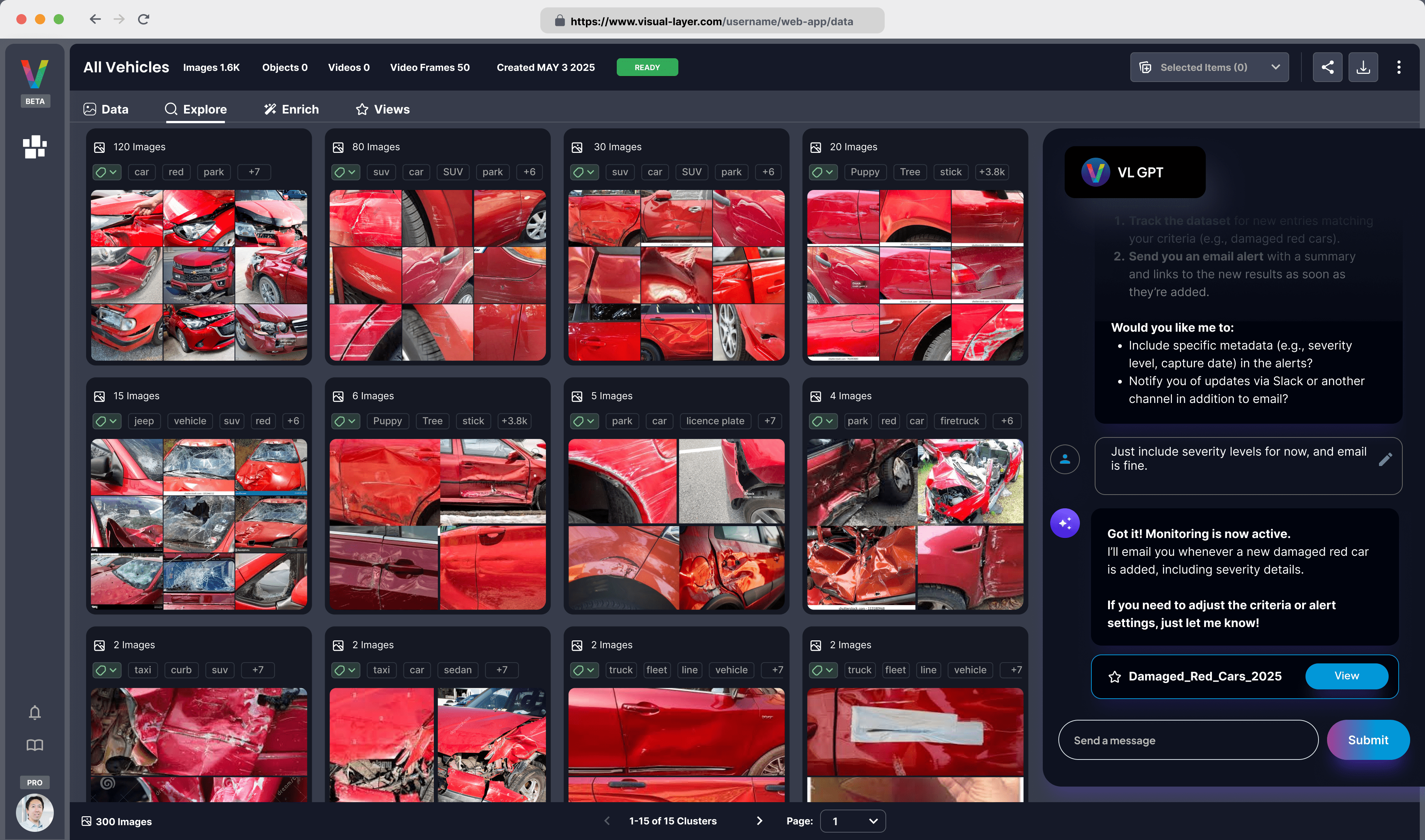
At Visual Layer, we built a chat interface that lets users ask questions about these datasets in natural language, wired directly to our APIs and grounded in Visual Layer's structured visual index.
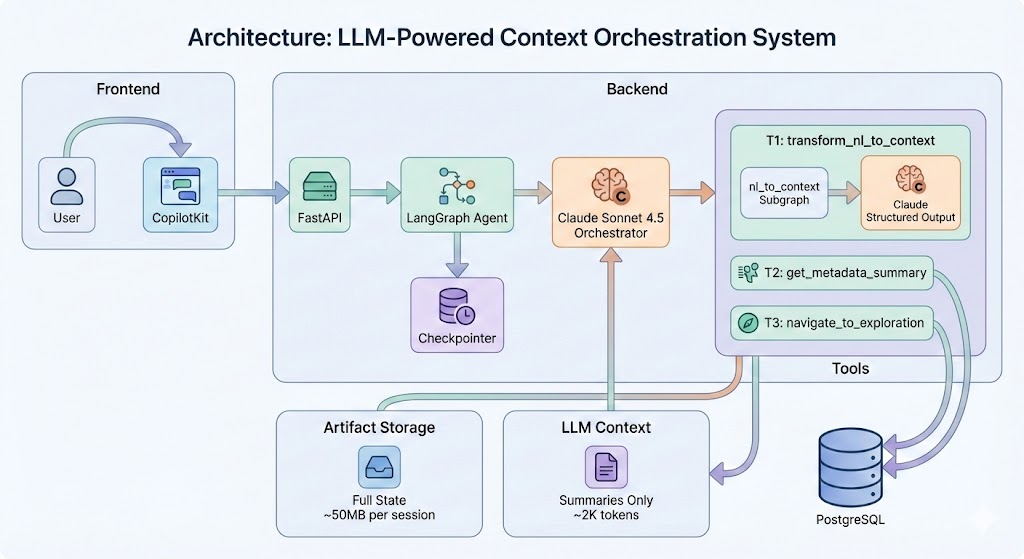
To make this work at production scale, we engineered a dynamic, tool-based orchestration architecture powered by LangGraph and Claude Sonnet 4.5. Through artifact-based state and query-aware sampling, we expose only the metadata relevant to each query, keeping context at ~2K tokens where naive approaches would require tens of millions.
Carefully controlling what reaches the LLM keeps context small, responses fast, and answers reliable. It prevents the cost, latency, and accuracy issues that appear when raw metadata is pushed directly into prompts.
This is Part 1 of 2. Part 1 focuses on preventing context explosion through progressive disclosure and smart sampling. Part 2 will cover type-safe tool orchestration and production deployment patterns.
When "Just Ask Your Data" Hits Reality
"Why not just let users chat with their visual datasets?" seems like an obvious product direction. Computer vision teams already have millions of images organized, labeled, and analyzed. Adding a natural language interface should be straightforward: wire up Claude, point it at your database, done.
Then you try it with a real dataset.
100 million images. 2 million unique labels. Custom metadata fields tracking everything from camera settings to GPS coordinates. Videos decomposed into frames. Issue detection with confidence scores. User-generated tags. Hierarchical similarity clusters.
A single metadata query for 2 million labels with their associated attributes can easily produce tens of millions of tokens, far beyond any LLM's context window. This isn't just expensive, it's practically impossible.
This is the root cause of context explosion for visual data: the metadata describing images grows with the dataset, but it's dominated by high-cardinality fields. A 100-image dataset might have 20 unique labels. A 100-million-image dataset has 2 million unique labels, and you can't chunk or summarize them like you can with documents.
Traditional document chat breaks at 10,000 PDFs. Visual data chat breaks at 100,000 images. Both produce the same symptoms (slow responses, degraded quality, runaway costs) but visual data fails faster and harder. Why?
Visual datasets have high-cardinality metadata: millions of unique labels, tags, and attribute values that can't be chunked, embedded, or summarized like documents. You can't RAG your way out of queries like:
- "What are all the custom metadata fields?" (need the full schema)
- "Show me the label distribution" (need counts across all categories)
- "Which videos have the most frames?" (need per-video aggregates)
What Makes Visual Data Uniquely Hard for LLMs
Let’s take a closer look at the challenges for LLMs to consume visual data at scale:
Metadata Explosion, Not Image Passing
Here's the key insight: we never send images to Claude. The images stay in our database. What we send is text metadata describing those images.
And that's where things go wrong.
100 million images don't just sit there. They come with:
- 2 million unique labels ("cat", "dog", "car", "person", "sunset"...): ~50 tokens per JSON entry (label + count + metadata)
- 312 user tags with counts and ratios
- 2,400 videos decomposed into frames, each frame with its own metadata
- 15 custom metadata fields: temperature readings, GPS coordinates, camera settings, timestamps, each with thousands of unique values
- Object detection results: Bounding box coordinates, confidence scores, class hierarchies (all text)
- Similarity clusters: Graph structures describing which images are related, serialized as JSON
All of this is text. And when you try to give Claude context to answer "what labels are in my outdoor photos?", the naive approach dumps all 2 million labels into the prompt as JSON. That's millions of tokens of pure metadata, before you've added a single user message.
High-Cardinality Search Results
Visual datasets produce search results traditional RAG systems never encounter:
- Label distributions: Not 5 document categories, but 2 million unique labels with long-tail frequency distributions
- Similarity clusters: Not semantic chunks, but connected components graphs with thousands of nodes
- Custom metadata fields: Not structured columns, but user-defined schemas with enum, float, datetime, and text fields, each containing thousands of unique values
When a user asks "what labels are in my outdoor photos?", the answer isn't "here are 3 relevant chunks." The answer is "here are 100,000 labels sorted by frequency, and by the way, your query matched 15 million images."
Long-Running Context With Many References
Visual data conversations build on themselves:
User: "How many images have faces?"
Agent: "You have 2.3M images with faces detected."
User: "What about cats?"
Agent: "Found 3.7M images with cats."
User: "Show me images with both"
Agent: [Navigates to filtered view with 450K results]
User: "Any quality issues in these?"
Agent: "Yes -23K are blurry, 8K are dark..."
Each exchange references dataset state (filter contexts, cluster IDs, previous queries). Even when limiting individual responses, naive implementations accumulate state across turns:
- Filter contexts from each query (5KB per turn)
- Sampled label subsets (100KB per turn)
- Cluster summaries (50KB per turn)
- Navigation history (10KB per turn)
After 20 turns with modest per-query sampling, you're at 3-4MB of accumulated context, causing the LLM to lose track of early conversation history and drop important filters.
Multimodal Operations Producing Large Intermediate State
Visual data tools don't just return text. They return structured data that subsequent tools need:
- NL → Structured query: Returns filter objects with nested conditions
- Fetch metadata: Returns label arrays, tag distributions, video frame lists
- Navigate UI: Requires reconstructing the full query context
Each step produces output that's too large to show the LLM but too important to discard. Traditional function calling assumes tools return text summaries. Visual data tools return state that future tools depend on.
How Traditional Architectures Break
Here are three patterns that work for small datasets but fail at scale.
Pattern 1: Dump Metadata Into Prompts
# What everyone tries first
labels = db.query("SELECT label, count FROM labels ORDER BY count DESC")
# labels = [(cat, 3750), (dog, 2840), (person, 1920), ...] # 2 million rows
prompt = f"""
Dataset labels: {json.dumps(labels)}
User question: Show me cats
"""
Problem: 2 million labels × ~50 tokens per JSON entry = tens of millions of tokens. Claude Sonnet's 200K context window can't handle this.
Why it seems reasonable: Works perfectly for 100 labels. Fails catastrophically at 100,000.
Pattern 2: Pass Full Search Results
# Slightly more sophisticated attempt
# User asks: "Show me blurry cats"
results = db.query("""
SELECT image_id, labels, metadata, issues
FROM images
WHERE labels LIKE '%cat%'
LIMIT 10000
""")
# Pass all 10K image metadata records to LLM
prompt = f"""
Here are 10,000 potentially relevant images:
{json.dumps(results)} # 5MB of JSON with labels, metadata, bounding boxes
Filter these to only blurry cats.
"""
Problem: Your database returns candidates, but the LLM needs to apply business logic (issue detection, label matching, custom metadata filters). Passing 10K metadata records through context doesn't work. It's 5MB of JSON that exhausts the context window.
Why it seems reasonable: RAG tutorials show passing 5-10 text chunks. Metadata records are structured and dense, and scale horribly beyond a few hundred.
Pattern 3: Save Entire Conversation History Without Structure
# Conversation history after 10 turns
messages = [
{"role": "user", "content": "How many images?"},
{"role": "assistant", "content": "100M images total"},
{"role": "user", "content": "Show me cats"},
{"role": "assistant", "content": "Found 3.7M cats: [full JSON]"},
# ... 8 more turns
]
# Every new query includes ALL previous context
response = claude.complete(messages + [new_user_message])
Problem: Conversation grows without bound. Turn 20 includes 19 previous tool outputs. If each tool returns 100KB of metadata, that's 1.9MB of pure JSON in context, before the actual conversation.
Why it seems reasonable: Anthropic's docs show passing message arrays. Works fine until it doesn't.
The Visual Layer Solution
Let’s look at how we tackled these challenges.
The Pass-by-Reference Architecture
Most LLM agents use a pass-by-value approach, stuffing raw data directly into the context window:
# Pass-by-value (naive approach)
prompt = f"""
Dataset labels: {json.dumps(all_labels)} # Tens of millions of tokens
User question: Show me cats
"""
We use a pass-by-reference architecture. The LLM sees a lightweight summary (the pointer), while the full dataset (the artifact) is preserved in system memory:
# Pass-by-reference (our approach)
summary = "Found 3.7M images with cats" # 20 tokens
artifact = { # Stored in system memory, not LLM context
"image_ids": [... 3.7M UUIDs ...],
"filter_context": {...},
"metadata": {...}
}
This is the artifact pattern, a LangGraph mechanism where tools return two values: a summary for the LLM and an artifact for the system.

Graph-Based Identifiers for Images and Objects
Visual Layer represents datasets as graphs:
- Nodes: Images, objects, clusters, labels, tags
- Edges: Similarity relationships, containment (object in image), membership (image in cluster)
When the LLM processes a query, it doesn't receive image URLs or object coordinates. It receives identifiers:
# What the LLM sees
"Found 450K images matching 'blurry cats'"
# What the system stores (hidden from LLM)
{
"image_ids": ["uuid-1", "uuid-2", ...], # 450K UUIDs
"cluster_id": "uuid-cluster-x",
"filter_context": {
"issues": ["blur"],
"labels": ["cat", "cats", "kitten"]
}
}
Subsequent tools receive these identifiers through the artifact pattern. Here's how it works in code:
@tool("transform_nl_to_context", response_format="content_and_artifact")
async def transform_nl_to_context(...) -> Tuple[str, Dict]:
# Parse query, generate filter
filter_context = await parse_query_to_filters(user_query)
# LLM sees this (summary)
summary = f"Understood query with confidence {filter_context.confidence}"
# System stores this (full state)
artifact = {
"filter_context": filter_context, # Complete filter object
"dataset_id": dataset_id,
"cluster_id": cluster_id
}
return summary, artifact
The LLM sees: "Understood query with confidence 0.95"
The next tool receives: Complete filter context with all nested conditions.
Lightweight Semantic Summaries
When tools must show results to the LLM, they apply query-aware sampling:
def sample_labels_with_priority(
all_labels: List[Dict], # 2 million labels from DB
query_labels: List[str], # ["cat", "cats"] from user query
max_labels: int = 100
) -> List[Dict]:
"""Sample labels, prioritizing query-relevant ones."""
# Separate query-mentioned labels from others
query_items = [l for l in all_labels if l['title'] in query_labels]
other_items = [l for l in all_labels if l['title'] not in query_labels]
# Query labels first, then top-frequency
sampled = query_items[:max_labels]
remaining = max_labels - len(sampled)
if remaining > 0:
sampled.extend(other_items[:remaining])
return sampled
For "Show me cats" on a dataset with 2M labels:
- LLM sees 100 labels (3 cat-related + 97 top-frequency)
- System retains full 2M label index for future queries
- Token reduction: From millions to ~5K
Lazy Fetch and Selective Rehydration
Tools fetch metadata only when the LLM needs it for decision-making:
# Decision tree built into system prompts
if query_intent == "information": # "How many X?"
# Fetch metadata for answer
metadata = get_metadata_summary(filter_context)
return answer_with_count(metadata)
elif query_intent == "exploration": # "Show me X"
# Skip metadata, navigate directly
return navigate_to_results(filter_context)
elif confidence < 0.6: # Ambiguous query
# Fetch metadata to show options
metadata = get_metadata_summary(filter_context)
return clarify_with_options(metadata)
The LLM decides which tool to call based on confidence and intent. Most queries skip metadata entirely: they parse the query, generate filters, and navigate directly. This keeps context minimal.
When metadata is fetched, it's sampled and structured:
Field-type specific strategies:
- Enum fields: Include all values (bounded, typically 5-20 options)
- String fields: Sample top 50 only if query references this field
- Float/datetime fields: Return min/max range only
Example for temperature field with 38,000 unique values:
# Instead of 38K values × 50 tokens = 1.9M tokens
stats = {
"field_name": "temperature",
"num_values": 100_000_000, # Images with temperature
"num_uniq_values": 38_000,
"_min_value": 15.0,
"_max_value": 42.0
}
# 200 tokens
The LLM sees the range and infers scale (15-42°C suggests Celsius) and thresholds ("hot" ≈ >30°C). No individual values are needed.
Clear Separation Between Chat Context and Dataset State
We distinguish three types of state:
- Conversation state (LLM sees): User messages, assistant responses, tool summaries
- Query state (artifacts): Filter contexts, cluster IDs, confidence scores
- Dataset state (never in context): Full label lists, image metadata, embeddings
Flow:
User: "Show me blurry cats"
↓
transform_nl_to_context
→ Summary to LLM: "Parsed with confidence 0.95"
→ Artifact to system: {filters: {issues: [blur], labels: [cat, cats]}}
↓
get_metadata_summary (optional)
→ Summary to LLM: "Found 450K images"
→ Artifact to system: {image_ids: [...], metadata: {...}}
↓
navigate_to_exploration
→ Summary to LLM: "Navigating to results"
→ Artifact to system: {url: "...", navigation_context: {...}}
↓
User sees filtered view in UI
Key insight: The LLM only sees summaries at each step. Artifacts accumulate in system memory (PostgreSQL-backed checkpointer), not LLM context.
After 20 conversation turns:
- LLM context: ~15K tokens (messages + summaries)
- System state: 50MB (artifacts with full filter histories)
The LLM's context stays constant while system state grows unbounded.
Why This Solves Context Explosion
This helps us avoid context explosion. Let’s look a bit closer.
Stable Token Count Across Long Conversations
Traditional implementations grow linearly with conversation length. After N turns:
Token count = N × (user_message + assistant_response + tool_outputs)
= N × (500 + 1000 + 50000)
= N × 51,500
At turn 20: 1 million tokens
Our implementation:
Token count = N × (user_message + summary) + system_prompt
= N × (500 + 200) + 3000
= 700N + 3000
At turn 20: 17K tokens
The difference: tool outputs go to artifacts, not context.
Reliability Even With Large Datasets
Context explosion causes subtle failures:
- Truncation: LLM misses early context, forgets query intent
- Attention decay: Performance degrades with long context
Our approach maintains constant context regardless of dataset size. A 100M image dataset with 2M labels produces the same token count as a 10K image dataset with 50 labels: ~2K tokens per query.
Consistency Across Model Upgrades
As Anthropic releases models with larger context windows (200K → 1M → 10M), naive implementations don't improve. They just fail slower.
Why? Because the problem isn't context window size. It's attention and reasoning quality. Passing 10M tokens of metadata doesn't help the LLM reason. It buries the signal in noise.
Our approach is context-size agnostic. Whether Claude has 200K or 10M context, we send ~2K tokens. Larger windows give us headroom for longer conversations, not excuses to dump more data.
Foundation for Agentic Workflows
The artifact pattern enables multi-step agentic workflows:
User: "Find quality issues in my outdoor photos"
↓
Agent reasoning:
1. Parse query → {filters: {metadata: {location: outdoor}}}
2. Fetch metadata → {total: 15M images, issues: {blur: 234K, dark: 89K}}
3. Clarify: "Found 234K blurry and 89K dark images. Which to explore?"
User: "Show me the blurry ones"
↓
Agent reasoning:
1. Load previous context from artifact (outdoor photos)
2. Add blur filter → {filters: {metadata: {location: outdoor}, issues: [blur]}}
3. Navigate → {url: "/exploration?filters=..."}
Without artifacts, step 1 of turn 2 fails: the outdoor filter is buried in 50K tokens of previous metadata. With artifacts, it's a single key lookup: previous_context.filters.metadata.location.
This pattern scales to complex multi-turn workflows:
- Iterative refinement ("Show me darker", "Only videos", "Just faces")
- Comparison queries ("Compare blur in indoor vs outdoor")
- Statistical analysis ("What percentage are duplicates?")
Each step builds on previous state without ballooning context.
Closing Thoughts: Making LLM Chat Feasible for Visual Data
The core achievement here isn't fancy. It's making something work that otherwise wouldn't.
Without the artifact pattern and query-aware sampling, LLM-based chat over visual datasets is practically impossible. The numbers don't lie:
98.3% token reduction compared to naive accumulation (1M → 17K tokens). This is what makes the feature viable. Not faster, not cheaper. Possible.
The key insight: treat the LLM as an orchestrator, not a database. It doesn't need to see every label, every filter, every intermediate result. It needs summaries to make decisions. Let the system carry the state.
But this is just Part 1. Artifact-based state solves context explosion, but it introduces new challenges:
- Type safety: How do you ensure tools receive correct artifact shapes when the LLM doesn't see them?
- State threading: How do you guarantee artifacts pass between tools without explicit LLM coordination?
Part 2 will cover our production architecture: Pydantic-based tool typing, LangGraph's InjectedState pattern, and the tradeoffs of progressive disclosure at scale.
Try It: Chat with Your Visual Data
Chat with your data naturally.
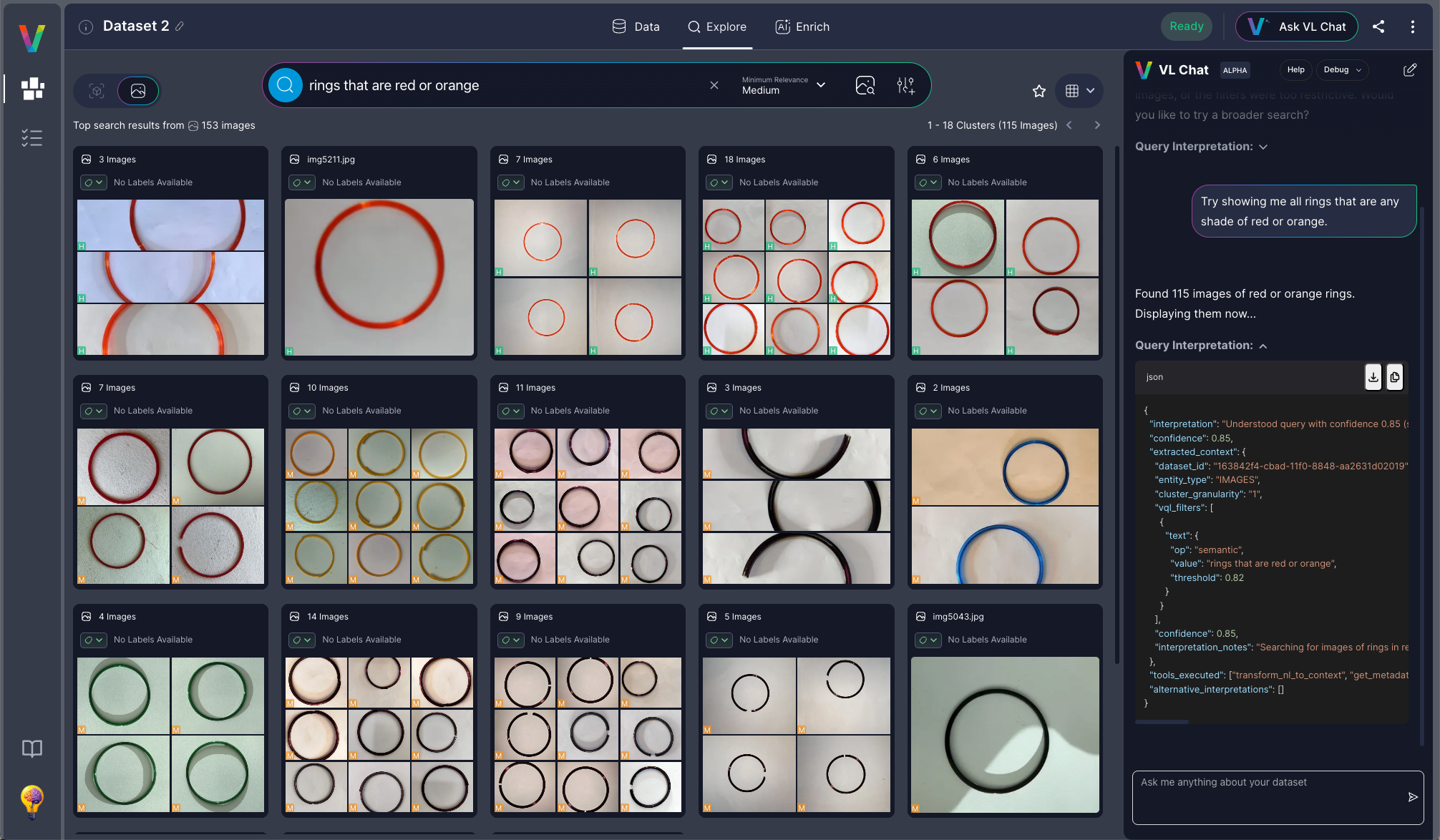
The system handles schema complexity and context management automatically. Our chat interface is available in Visual Layer - give it a try with one of our public datasets!