


TL;DR
- The evolution of visual data infrastructure is critical for enhancing AI model performance and reducing data preparation burdens.
- Visual data is evolving from raw files to structured, searchable assets, similar to the transformation seen in text data.
- At Visual Layer we share enriched datasets on Hugging Face, fostering community collaboration and validation of our technology, exemplifying the importance of community-driven data sharing and improvement.
- Researchers utilize enriched datasets for machine-readable metadata, allowing efficient filtering of low-quality samples. The Visual Layer technology enables quick data curation, reducing weeks of manual cleaning.
Introduction
For the past few years, a quiet revolution has been happening with text data. What used to be collections of raw, static files have transformed into structured, searchable, and enriched assets. Text became infrastructure.
Now, that same transformation is happening for visual data. At Visual Layer, our technology is built on a simple premise: the quality of your data determines the performance of your model. We build the tools to find and fix data issues at scale. But as developers, we also believe "the proof is in the pudding".
That's why we share our enriched datasets on Hugging Face. It’s our way of contributing to the community, but it also serves as a public proving ground for our technology-first approach to data curation.
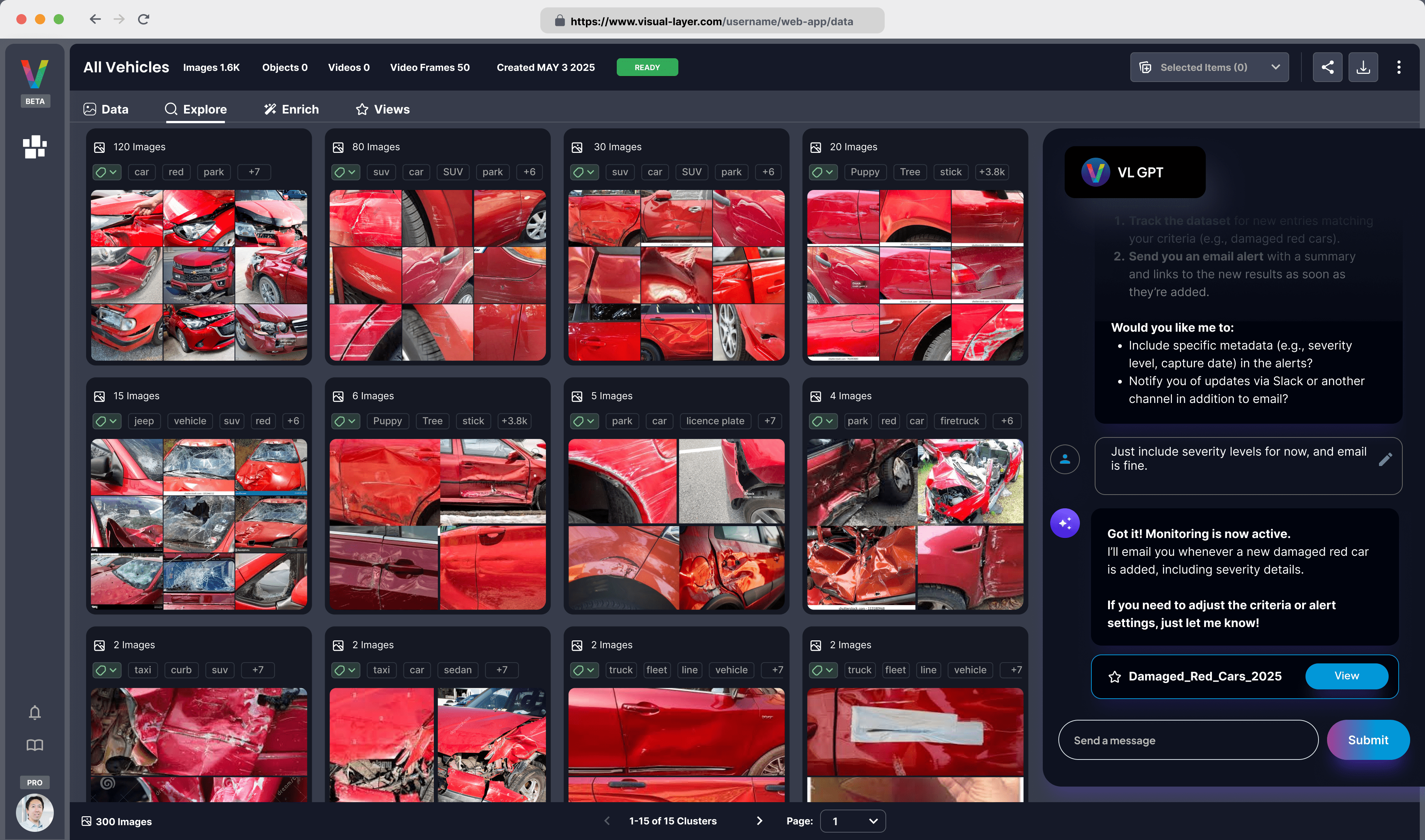
As a direct result, developer adoption is rapidly increasing. Independent researchers and teams are integrating Visual Layer's structured, enriched datasets into their production-grade AI pipelines. Crucially, this use constitutes a public, real-world peer review and validation of the data's quality, creating a powerful feedback loop. The adoption proves the thesis that making visual data searchable accelerates analysis.
The Rise of the Developer-Centric Dataset
Developer adoption is the ultimate, real-world peer review. You can see the objective evidence of this in action with the c2ot-imagenet32-fm flow matching model.
The researchers behind it needed to train a highly sensitive generative model, an architecture notoriously vulnerable to data noise. They chose our Imagenet-1k-vl-enriched dataset on Hugging Face, and their public results show how they achieved a top-tier FID score of 5.350. In their paper, "The Curse of Conditions" (arXiv:2503.10636), the authors cite our work, stating they used the captions provided by Visual Layer for their experiments.
This is the key. Adoption is accelerating because researchers are actively seeking datasets that are already structured, enriched, and ready for production use.
Leading the Revolution: What "Visual Data as Infrastructure" Means
Our tech-first philosophy is why researchers choose our data. We build the essential infrastructure by transforming raw files, focusing on three principles:
- Enriched captions
- Machine-readable quality
- Annotation consistency
This approach turns passive datasets into active AI infrastructure, letting developers build models instead of cleaning data.
Enrich Data for the Task at Hand
A simple class label such as "golden retriever" is useless for generative models. A model can't learn how to create "a golden retriever running on grass" from just those two words.
When a model's only input is such a simple label, it is forced to learn an "average" of every golden retriever in the dataset. But in reality, it can never learn the specific nuances that distinguish one picture from another. Instead of learning detailed features, the model identifies only the most common characteristics, resulting in a single, "blurry" internal representation. This prevents it from making accurate or nuanced predictions on new, specific images.
In essence, "garbage in, garbage out" applies. The model wastes resources trying to decipher context that simply isn't there.
In essence, "garbage in, garbage out" applies.
Conversely, by adding a detailed caption like "a golden retriever running on grass," we provide the model with additional, crucial context from which to learn. This, known as caption conditioning, helps the model learn the important nuances before wasting resources and generating an incorrect image. Moreover, adding pre-computed embeddings, CLIP vectors, or any other metadata makes the data semantically searchable before it ever hits a training loop, enabling the user to also find the "needle in the haystack" quickly and almost effortlessly, not just for generating images but for other use cases as well. This is why the Visual Layer enrichment technology is fundamental.
Example: The Visual Layer enrichment was critical for the c2ot team. Their model is caption-conditioned, and they explicitly used the captions Visual Layer provided as the input conditions to achieve their results.
Make Data Quality Machine-Readable
At scale, you cannot fix what you cannot find. All large-scale datasets contain "garbage" such as duplicates, mislabels, and blurry photos. Training on this raw noise is a disaster. To make insights discoverable, we build technology to include comprehensive, machine-readable metadata.
Example: Our imagenet-1k-vl-enriched dataset includes an "issues" column that programmatically flags potential problems. This isn't just a single model; it’s a full battery of analysis tools:
- Quality Analysis: Flags blurry, dark, or low-contrast images.
- Embedding Analysis: Finds unique outliers or mislabels.
- Duplicate Detectors: Identifies exact and near-duplicates that skew training.
This is the tech that allows any developer to programmatically filter a dataset in minutes. We know it works because we used it on LAION-1B to identify over 100 million duplicates. We shared this core technology as the open-source tool fastdup, and now the community uses it for the same purpose.
Example: Community developer Gerold Meisinger used fastdup while training a ControlNet model on the laion-art dataset. In his Hugging Face README, he calls it "a mandatory step." He identified that ~40% of his 180,000 images were low quality or duplicates. By removing ~76,000 "bad" images, he stopped the model from "memorizing" duplicates and improved accuracy.
This "mandatory step" is the dividing line that separates those capable of taking the next leap in computer vision from those getting left behind. But beyond technical metrics, what does "garbage" actually cost you?
- Direct Compute Waste: Training on 100 million duplicates means paying for the same GPU cycles repeatedly.
- Model Skew: If 10% of your dataset is duplicates of one concept, your model learns that concept is 10x more important.
- Corrupted Validation: If your validation set contains duplicates from training, your accuracy score is a lie.
Making quality "machine-readable" data is the only way to build a model you can actually trust. This is the entire "data as infrastructure" feedback loop in action.
Prioritize Annotation Consistency
Inconsistent annotations are a damaging form of noise. When one annotator draws a tight bounding box and another draws a loose one, the model receives conflicting signals. Annotation noise is one of the most pervasive issues in computer vision. It is often driven by the human tendency for rules and standards to slowly shift over the course of a multi-week labeling project. The strict criteria your team applied on Day 1 are rarely the same criteria applied on Day 30 (unless your very experienced annotators continue to reference those rules every single day).
Example: The c2ot model relied on 32x32 pixel images. That is a canvas of only 1,024 total pixels. Imagine your target object is a 10x10 pixel box. If an annotator on Day 30 drifts and draws a "loose" 14x14 box instead, they have nearly doubled the pixel count for that object and fundamentally corrupted the object-to-background ratio. The model is now being fed conflicting training signals:
- a precise, confined location ("The object is in this small, exact box")
- a vague, broader one ("The object is in this larger, looser box").
The model cannot reconcile these conflicting objectives and thus fails to learn effectively.
By algorithmically analyzing and standardizing the ImageNet-1k bounding box annotations, fixing inconsistencies, correcting boxes that cut off parts of the object, and ensuring consistent treatment, Visual Layer provided the c2ot model with a coherent spatial prior. Consequently, the model could stop fighting annotation noise and focus its limited capacity on learning semantic content, which is a core requirement for generating clear images at such low resolutions.
The Future: A Symbiosis of Technology and Collaboration
The best datasets actively remove friction. With the c2ot model, researchers could focus entirely on their novel flow-matching architecture because our enriched dataset meant they didn't have to waste weeks building cleaning pipelines. This is "data as infrastructure" in action.
This mindset is even more critical for complex modalities like video. To most, a video dataset is just a folder of thousands of MP4s. That is not infrastructure; that is a storage problem. To find "all 5-second clips of a person running," you typically have to build a massive pipeline to load, decode, and infer on every single file.
"Video as infrastructure," conversely, is a database where files are pre-processed, enriched, and indexed. A developer can replace a multi-week project with a simple query:
- "Give me all clips where a scene cut occurs."
- "Find timestamps where (action: 'person running') and (object: 'dog') co-occur."
- "Exclude any frames flagged as (quality: 'blurry')."
This creates a new baseline dependent on a tight feedback loop with the community: Visual Layer provides the production-ready asset (the clean, enriched dataset), and Hugging Face provides the collaborative hub for discovery.
This combination creates a public record of what works, directly linking data assets to performance outcomes. As the examples we’ve shared confirm, by making visual data searchable and structured, we can all move past the friction of manual data work and get back to what matters: building better models.
About Visual Layer
The journey from raw data to a production-ready asset is a massive challenge. You don't have to build that infrastructure alone. Our experts are ready to consult with you to understand your environment, your data, and your mission. We can build a customized plan to help you move from data chaos to clear, actionable insights.