TL;DR
- AI success starts with high-integrity data. Poor-quality, mislabeled, or duplicate data silently derails model performance, drives up compute costs, and slows time to market.
- At scale, teams lose visibility, unable to detect hidden issues that introduce bias, weaken generalization, and erode trust.
- Automating dataset curation and governance is no longer optional; it’s foundational to building reliable, cost-effective AI systems.
The Hidden Tax on Artificial Intelligence
Your teams are building the future with AI. They have the best algorithms and the fastest hardware. But they're being held back by a problem hiding in plain sight: their data. Before it can be used, this data is effectively invisible,a vast, unstructured digital ocean inaccessible to both humans and machines.
Attempting to train a model on this raw, chaotic data is like flying blind. You can't fix what you can't see. This foundational challenge isn't just a technical problem; it's a massive financial drain. Gartner found that organizations lose an average of $15 million annually due to poor data quality. This "hidden tax" on your operation is paid in wasted compute cycles, frustrated data scientists chasing phantom bugs, and unreliable production models that ultimately erode trust.
The Scale of the Problem: A Fundamental Blind spot
Modern visual datasets are massive, often aggregated from countless sources. At this scale, manual quality assurance is impossible, a human reviewer inspecting one image per second would need over 11 days to review just one million images.
This immense scale creates a fundamental blind spot. Teams are forced to "fly blind," making dangerous assumptions about their data's integrity. Traditional validation methods are often flawed:
- Lack of context is a silent killer of data integrity, leading to misinterpretations, erroneous analyses, and flawed decision-making.
- Inefficient Validation: Having multiple people review the same data point is expensive and inefficient, as most data may not require multiple reviewers. The challenge is identifying which data is most likely to be incorrect in the first place.
- Problematic Iteration: AI models can’t be trusted if the data feeding them is flawed, and at scale, even humans can’t reliably spot what’s broken. Teams often clean data iteratively without full context, introducing subtle biases and blind spots. This leads to faulty assumptions, statistical traps like Simpson's Paradox, a common pitfall where even perfectly accurate data points to a flawed conclusion when analyzed in aggregate, because a critical underlying variable (like the source of the data) is ignored (Krishnan et al., 2016). The result: models then look accurate but fail in the real world. Without deep visibility and automated validation, both humans and machines are flying blind,and the costs compound across every stage of development.
- High-Dimensional Sensitivity: Modern, high-dimensional statistical models are extremely sensitive to sample size. This means that simply cleaning a small sample of data to perfection may still result in an inaccurate model, making the strategy for cleaning just as important as the act of cleaning itself.
The result is a flawed foundation where hidden biases are baked in from the very start.
Common Data Quality Issues and Their Consequences
1. Duplicate Data
Duplicate images may seem minor, but their impact is exponential. This isn't theoretical; an analysis of the massive LAION-1B dataset found over 90 million duplicates, representing 10% of the entire dataset.
- Budget Drain: Wasted costs go beyond storage to include data transfer fees and compute power used for preprocessing redundant images.
- Slower Workflows: Duplicates cause data loading bottlenecks and can extend model training times by up to 3x with no learning benefit.
- Unreliable Models: Duplicates give a false sense of data volume while severely skewing class balance. If a dataset has 100 images of "dogs," but 30 are copies of the same golden retriever, the model becomes an expert at recognizing that specific dog but fails to generalize to other breeds. This unreliability has significant social consequences. Landmark research from the 'Gender Shades' project, for instance, revealed that commercial facial recognition systems had far higher error rates for darker-skinned women, a direct result of biased training datasets.
2. Outliers and Low-Quality Images
Outliers are technically correct but contextually wrong images that can poison the learning process. In the high-stakes world of autonomous driving, failing to train on enough edge cases can lead to tragedy. In the fatal 2018 Uber self-driving car crash, the system detected the pedestrian but failed to correctly classify her or brake in time,a catastrophic failure in handling an outlier. Similarly, a medical AI trained on pristine X-rays can be thrown off by an image with a small metal artifact, potentially leading to a dangerous misdiagnosis.
Low-quality images (dark, blurry, or overexposed) are also problematic. A model trained on noisy data may learn that "blurriness" is a key feature of the object it’s supposed to identify, causing it to fail on clear, high-resolution images.
3. Mislabeled Data
Incorrect labels are one of the most damaging issues. They teach a model incorrect patterns, creating a domino effect of semantic confusion. The consequences range from brand-damaging incidents, such as when Google Photos notoriously mislabeled images of Black people as "gorillas," to more severe outcomes. The math is stark: in a 10 million image dataset, a 1% label error rate creates 100,000 incorrect training signals.
This problem also represents a massive loss of productivity. A Forrester report found that nearly one-third of data analysts spend more than 40% of their time just vetting and validating data before it can be used.
From Data Chaos to Decisive Advantage: A Framework for Building AI-Ready Datasets
No algorithm, no matter how advanced, can overcome the fundamental flaw of “garbage in, garbage out.” These challenges prove that ad-hoc fixes are insufficient, not to mention the aspect of time, often taking days or even months.
Building trustworthy AI requires a new, systematic framework for creating high-integrity data, built on four key pillars:
Systematic Error Detection: Unmasking the Hidden Flaws
You cannot fix what you cannot see. The first step in establishing data integrity is implementing an automated process to systematically identify errors at scale. This goes far beyond simple, rule-based checks. True systematic detection requires sophisticated algorithms that can find perceptual duplicates (resized or altered images), identify statistical outliers, and surface potential label errors by comparing images with similar embeddings but different tags.
Deep Contextual Analysis: Understanding the Data's DNA
Data quality isn't just about technical correctness; it's about contextual relevance. Effective teams need the ability to visualize their dataset's distributions to understand its inherent composition. This reveals critical class imbalances, helps identify underrepresented subgroups to ensure model fairness, and validates that the training data is a true reflection of the real-world environment where the model will be deployed.
Efficient, Scalable Remediation: From Weeks to Hours
Finding millions of errors is only useful if you can efficiently fix them. A scalable framework must include streamlined workflows that empower teams to take decisive action. This means moving beyond one-by-one fixes and enabling bulk operations, like removing entire clusters of duplicates or offering assisted correction for mislabels, to transform weeks of tedious manual labor into hours of focused curation.
Continuous Monitoring and Governance: Sustaining Quality Throughout the Lifecycle
Creating a quality dataset is not a one-time event. As new data is continuously ingested, a robust framework must include continuous monitoring to flag new quality issues and prevent "data drift." This, combined with strong dataset version control and clear data governance policies, ensures standards are maintained throughout the entire AI lifecycle.
How Visual Layer Helps
Visual Layer provides the foundational data integrity layer to systematically find and fix these hidden issues at enterprise scale. It is an AI-powered data quality platform purpose-built to help computer vision teams eliminate hidden dataset costs and maximize model performance.
- Automated Detection Finds What Humans Can't: The platform’s graph-based engine with multimodal relationship learning automatically analyzes your entire dataset to find duplicates, outliers, and quality issues. It can index billions of data points in under a day, automatically surfacing critical data quality issues and edge cases.
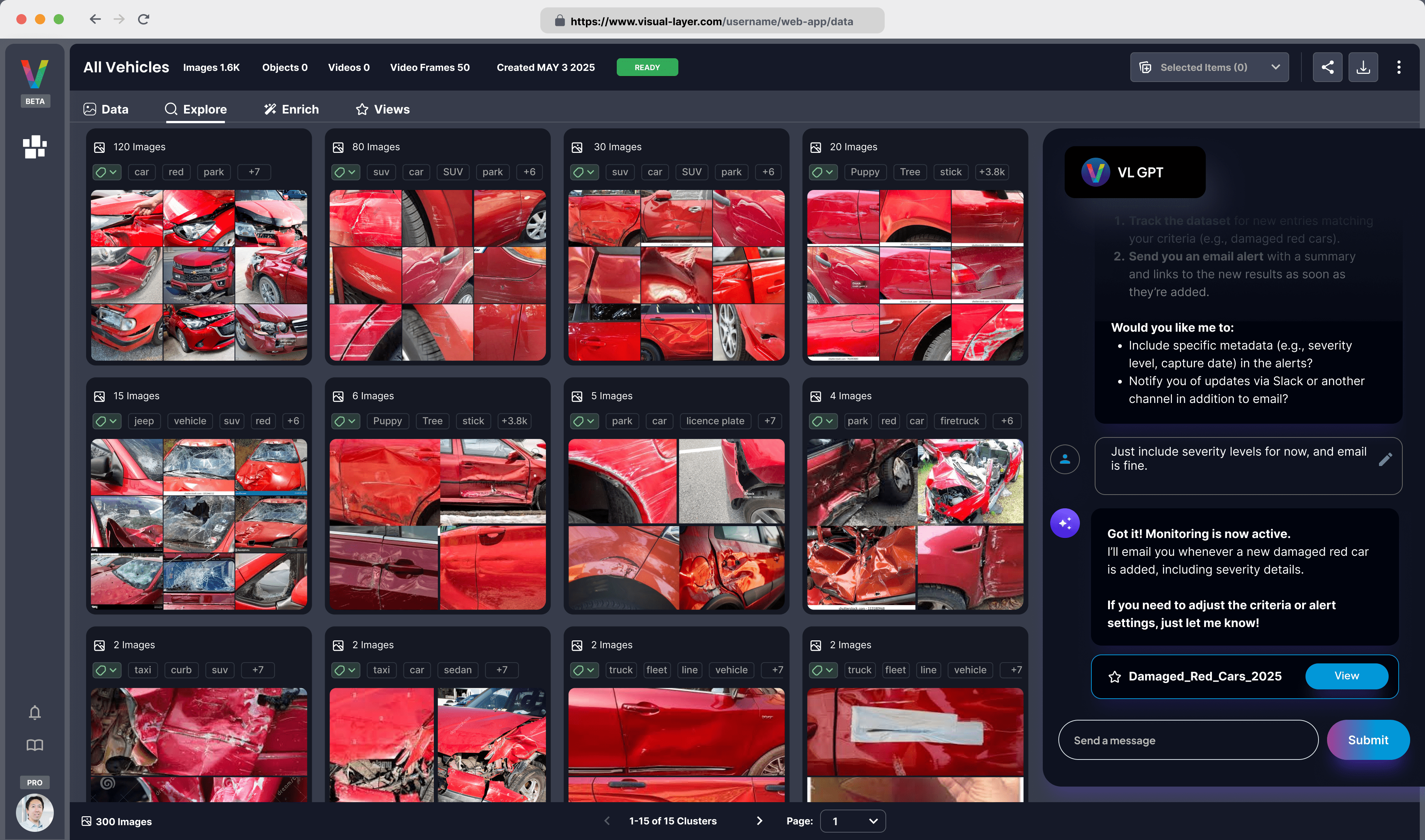
- Intuitive Visualization Speeds Up Review: You can explore your dataset visually, inspect data clusters at a glance, and filter by issue type. This allows your team to rapidly discover relevant training data, edge cases, and underrepresented classes.
- Efficient Workflows Enable Fixes at Scale: Instead of fixing issues one by one, you can manage them in bulk. The platform is designed to eliminate tedious, error-prone, and expensive manual cleaning. You can then export clean, curated datasets directly into your model training pipelines.
- Measurable Impact on Performance and Costs: After systematic data cleaning, teams often report a 20-50% reduction in overall dataset size while preserving critical diversity. This translates to dramatic, measurable improvements. Walmart saw a 10x reduction in AI training costs and a 25% increase in model quality. Elbit Systems achieved 50% more accurate models and reduced model generation time from 10 weeks to 1 week. Apple was able to respond to quality issues 20 times faster in its manufacturing operations.
- Flexible and Secure Deployment: Visual Layer can be deployed on-premise for sensitive data or in the cloud for flexible scalability, running wherever your data resides.
About Visual Layer
Visual Layer empowers AI practitioners and enterprises to turn massive, raw visual datasets into clean, curated, AI-ready datasets for building better models. Our platform transforms chaotic visual data into a strategic asset through automated detection of duplicates, mislabels, outliers, and quality issues. At its core, Visual Layer is an AI engine engineered for high-quality, scalable, and efficient visual dataset curation.
Eliminate Your Org's Hidden Data Costs
Learn more about how to eliminate hidden dataset costs and access the full potential of your AI.